
Investigating an apparent performance issue recently, I had variables including platform, product version, build type (debug vs release), compiler options, hardware, machine configuration, data sources and more. I was working with both our Dev and Ops teams to determine which of these seemed most likely in what combination to be able to explain the observations I'd made.
Up to my neck in a potential combinatorial explosion, it occurred to me that in order to proceed I was adopting an approach similar to the ideas behind chart parsing in linguistics. Essentially:
- keep track of all findings to date, but don't necessarily commit to them (yet)
- maintain multiple potentially contradictory analyses (hopefully efficiently)
- pack all of the variables that are consistent to some level in some scenario together while looking at other factors
Programming languages will generally be engineered to reduce ambiguity in their syntax in order to reduce the scope for ambiguity in the meaning of any statement. It's advantageous to a programmer if they can be reasonably certain that the compiler or interpreter will understand the same thing that they do for any given program. (And in that respect Perl haters should get a chuckle from this.)
But natural languages such as English are a whole different story. These kinds of languages are by definition not designed and much effort has been expended by linguists to create grammars that describe them. The task is difficult for several reasons, amongst which is the sheer number of possible syntactic analyses in general. And this is a decent analogy for open-ended investigations.
Here's an incomplete syntactic analysis of the simple sentence Sam saw a baby with a telescope - note that the PP node is not attached to the rest.
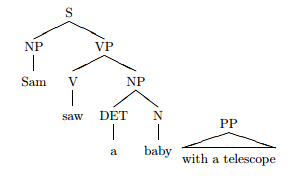
The parse combines words in the sentence together into a structures according to grammatical rules like these which are conceptually very similar to the kind of grammar you'll see for programming languages such as Python or in, say, the XML specs:
NP -> DET N VP -> V NP PP -> P NP NP -> Det N PP VP -> V NP PP S -> NP VPThe bottom level of these structures are the grammatical category of each word in the sentence e.g. nouns (N), verbs (V), determiners such as "a" or "the" (DET) and prepositions like "in" or "with" (P).
Above this level, a noun phrase (NP) can be a determiner followed by a noun (e.g. the product) and a verb phrase (VP) can be a verb followed by a noun phrase (tested the product) and a sentence can be a noun phrase followed by a verb phrase (A tester tested the product).
The sentence we're considering is taken from a paper by Doug Arnold:
Sam saw the baby with the telescopeIn a first pass, looking only at the words we can see that saw is ambiguous between a noun and a verb. Perhaps you'd think that because you understand the sentence it'd be easy to reject the noun interpretation, but there are similar examples with the same structure which are probably acceptable to you such as:
Bill Boot the gangster with the gunSo, on the basis of simple syntax alone, we probably don't want to reject anything yet - although we might assign a higher or lower weight to the possibilities. In the case of chart parsing, both are preserved in a single chart data structure which will aggregate information through the parse:
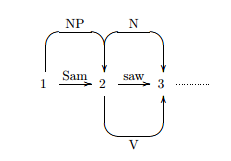
The chart data structure achieves this by holding information discovered in previous passes for reuse in subsequent ones, but crucially doesn't preclude some other analysis also being found by some other rule. So, although a baby fits one rule well, another rule might say that baby with is a potential, if contradictory, analysis. Both will be available in the chart.
Mapping this to testing, we might say that multiple experiments can generate data which supports a particular analysis and we should provide ourselves the opportunity to recognise when data does this, but not be side-tracked into thinking that there are not other interpretations which cross-cut one another.
In some cases of ambiguity in parsing we'll find that high-level analyses can be satisfied by multiple different lower-level analyses. Recall that the example syntactic analysis given above did not have the PP with the telescope incorporated into it. How might it fit? Well, two possible interpretations involve seeing a baby through a telescope or seeing a baby who has a telescope.
This kind of ambiguity comes from the problem of prepositional phrase attachment: which other element in the parse does the PP with the telescope modify: the seeing (so it attaches to the VP) or the baby (so NP)?
Interestingly, at the syntactic level, both of these result in a verb phrase covering the words saw the baby with the telescope and so in any candidate parse we can consider the rest of the sentence without reference to any of the internal structure below the VP. Here's a chart showing just the two VP interpretations:
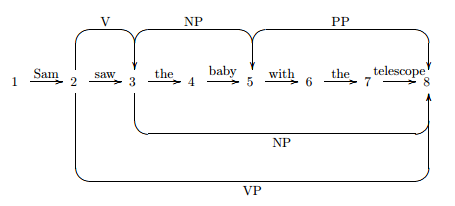
The example sentence and grammar used here are trivial: real natural language grammars might have hundreds of rules and real-life sentences can have hundreds of potential parses. In the course of generating, running and interpreting experiments, however, we don't necessarily yet know the words in the sentence, or know that we have the complete set of rules, so there's another dimension of complexity to consider.
I've tried to restrict to simple syntax in this discussion, but other factors will come into play when determining whether or not a potential parse is plausible - knowledge of the frequencies with which particular sets of words occur in combination would be one. The same will be true in the experimental context, for example you won't always need to complete an experiment to know that the results are going to be useless because you have knowledge from elsewhere.
Also, in making this analogy I'm not suggesting that any particular chart parsing algorithm provides a useful way through the experimental complexity, although there's probably some mapping between such algorithms and ways of exploring the test space. I am suggesting that being aware of data structures that are designed to cope with complexity can be useful when confronted with it.
Images: Doug Arnold, https://flic.kr/p/dxFxXG
As mentioned, multiple experiments can generate data which supports a particular analysis but Test Data should be considered in both positive and negative ways. Poorly designed test data may not test all possible test scenarios which will hamper the quality of the software. Test data can be used for positive testing to verify a given set of input to a given function if it produces an expected result and also used for negative testing to test the ability of the program to handle unusual, extreme, exceptional, or unexpected input.
ReplyDelete